De toda la vida, los sistemas informáticos han estado expuestos a sufrir incidencias y episódicos cortes de servicio, más o menos graves y resueltos en plazos generalmente breves. Siempre aislados, por definición. Ahora, en la era del cloud computing, el fenómeno se atenúa o se magnifica, según se mire; el colapso sufrido por EC2 (Elastic Compute Cloud), servicio de una filial de Amazon, es una advertencia que condicionará actitudes futuras. Un evento “en la nube” afecta a cientos, tal vez miles, de sistemas, multiplicando su impacto económico sobre empresas que han puesto un componente de su negocio al cuidado de un proveedor de servicios.
¿Qué ha ocurrido exactamente? A primera hora del jueves 21, Amazon Web Services reconocía que uno de sus centros de datos. radicado en Virgina (Estados Unidos) experimentaba “problemas de conectividad, latencia y ratios inusuales de errores”. Según la reconstrucción de los hechos, el origen fue una cadena de secuencias de backup que se replicaron hasta exceder el volumen disponible en los servidores de almacenamiento, hasta provocar una degradación en cascada del servicio a clientes cuyo único error fue contratar capacidad redundante en otras “zonas de disponibilidad” de EC2, que han seguido funcionando con normalidad.
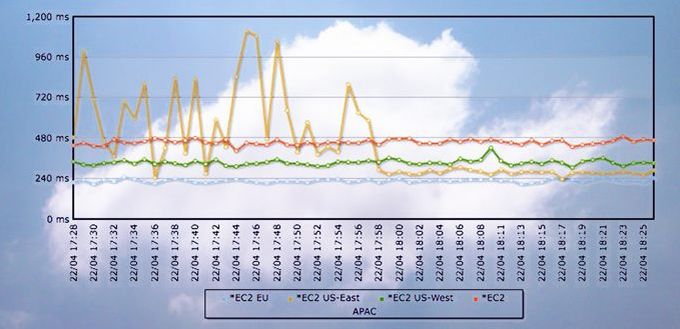
Se esperaba subsanar el problema rápidamente, pero en la práctica el incidente no empezó a resolverse hasta el viernes [el gráfico de Cetexis muestra la alteración de los tiempos de respuesta durante 60 minutos del día 22], pero anoche el cuadro de mando de EC2 seguía mostrando este mensaje del domingo 24: “el volumen de almacenamiento se está recuperando gradualmente”. Entre el jueves y el viernes pasados, decenas de sitios web – Foursquare, Reddit y Quora, los más notorios – que arriendan capacidad en los servidores de EC2 colapsaron temporalmente, e informaron a sus usuarios a través de Twitter. Lo que a su vez disparó las alarmas.

Pinchar imagen
Según la documentación de EC2, su servicio garantiza un 99,95% de disponibilidad en la zona contratada, durante los 365 días del año, pero recomienda “proteger sus aplicaciones de un eventual fallo en una única localización”. De hecho, otros usuarios más previsores, como The New York Times, Netflix y Zynga, siguieron funcionando gracias a esa protección adicional. Los servidores de EC2 están repartidos en grupos independientes, de modo que si uno falla, los otros mantienen vivo el servicio.
No consta que otras zonas hayan tenido problemas similares, y la que cubre Europa, radicada en Irlanda, ha funcionado sin interrupción. En una interpretación extrema, este episodio demostraria que la opción por cloud computing no es inmune a fallos que las empresas conocen en la modalidad on premise. Aun así, es improbable que por ello se debilite su atracción: un estudio de la consultora Booz & Co sostiene que la ratio coste-beneficio puede ser quince veces más baja para el ciclo de vida de una aplicación, si es alojada en la nube en lugar de un centro de datos o un hosting convencionales. De todos modos, la experiencia indica que incluso las empresas mejor dispuestas recurren a la nube sólo para tareas rutinarias, reservando para sí las más críticas.
Aunque Amazon – empresa opaca donde las haya, y este puede ser su punto flaco – no desglosa las cifras de su rama Web Services, lanzada en 2006, los analistas estiman para este año unos ingresos de 500 millones de dólares. Jeff Bezos, fundador y factotum de la compañía, espera que en algún momento llegue a aportar ingresos equivalentes a los de su negocio minorista. Quizás un día podría separar la rama del tronco, pero hoy sería imposible.
Nada más trascender lo ocurrido, empezaron a circular por Internet revelaciones de otros usuarios (no identificados) que de pronto han recordado problemas con las prestaciones de EC2. En cambio, los competidores, por aquello de las barbas del vecino, se han mantenido exquisitamente discretos. Microsoft ha dado instrucciones expresas de no presumir de la estabilidad de su servicio Azure, que funciona con reglas similares al de Amazon. Más locuaces, y positivos, fueron los portavoces de Rackspace, al comparar el fallo de EC2 con un accidente de avión: “el cloud computing, como el transporte aéreo, siempre será más seguro que viajar en coche o tener las aplicaciones en un centro de datos propio”.
El incidente tendrá, previsiblemente, como efecto la contratación de capacidad redundante – que puede hacerse en cuestión de minutos – para no incurrir en el riesgo. Asimismo, despertará el interés de los usuarios por examinar con detalle los contratos: no sólo el nivel de servicio (SLA) sino también el coste del backup y de la recuperación y, llegado el caso, las cláusulas de penalización.
.