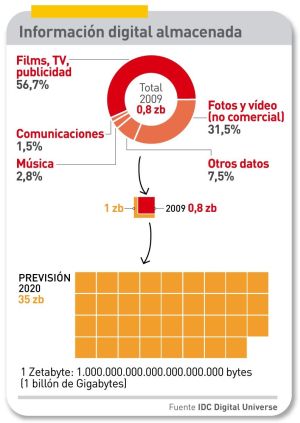
Había que encontrar una expresión descriptiva del enorme volumen de datos que desborda la capacidad del parque de sistemas informáticos; esta es la fórmula Big Data, que se ha acoplado a otro cliché de uso corriente, Cloud Computing. A medida que empresas y organismos acumulan información digital, se enfrentan a varias tareas ingentes: clasificar, filtrar, comprimir, almacenar, optimizar y analizar una masa de datos que en 2009 se calculaba en 0,8 zetabytes y en 2020 habrá crecido hasta 35 zetabytes [35 billones de gigabytes], una multiplicación por 44 en una década. Para entonces, la mitad de esos datos residirá, y será procesada, en servidores remotos “en la nube”.

Joe Tucci
Esto fue lo que congregó en Las Vegas a unos 10.000 clientes y partners de EMC, bajo el lema Cloud Meets the Big Data, para conocer esta tendencia que está transformando la industria de las TI. Las ponencias centrales estuvieron a cargo de Joe Tucci y Pat Gelsinger, chairman y presidente de la empresa convocante, y de Paul Maritz, CEO de su filial VMware.
El punto de partida de la conferencia fue este: no basta con almacenar los datos tal como se ha hecho durante décadas, ni el problema es sólo de magnitud. Más grave que el volumen, es la naturaleza de los datos que se acumulan: los nuevos sistemas de almacenamiento han de manejar datos no estructurados – búsquedas en internet, comunicaciones en las redes sociales, colecciones de fotos y vídeos (sobre todo, mucho vídeo), blogs y otros contenidos generados por los usuarios, o procedentes de sensores de tráfico, imágenes de cámaras de seguridad, historiales médicos, investigación genómica, geofísica, etc. – que requieren un tratamiento cualitativamente distinto al de las bases de datos tradicionales.
Históricamente, las bases de datos fueron diseñadas para facilitar transacciones, como la actualización de cuentas corrientes bancarias con los movimientos de un cajero automático. Pero tienden a ser rígidas y estructuradas según campos definidos de manera permanente, lo que marca un límite a lo que puede y no puede preguntarse a la base de datos. En contraste, las nuevas técnicas son capaces de manejar datos no estructurados, como los que típicamente circulan por internet.
Todo sumado, lo anterior justifica que se hable cada vez más de Big Data, y el auge de Internet ha jugado un papel: Google, Yahoo, Facebook, Twitter, Amazon, etc, han tenido que desarrollar sus propias técnicas para atender ese problema, técnicas que van más allá (y más al fondo) de aquello que durante años han permitido los sistemas informáticos de la banca y las grandes corporaciones. Un ejemplo: para Facebook es esencial comprender cómo se comportan sus más de 500 millones de usuarios, porque de esa comprensión dependen la optimización de su infraestructura y su argumentación para vender publicidad a los anunciantes que quieran llegar a esa masa de consumidores que, sin segmentación, sería amorfa. Con ese fin, la red social se ha dotado de unas 2.000 máquinas de almacenamiento con capacidad de 25 petabytes (22 millones de gigabytes). Google, con una capacidad muy superior, no facilita datos al respecto.
Para el resto de las empresas de casi cualquier sector, que confluyen masivamente en la red, esta ola de información digital significa que, por primera vez, disponen de instrumentos para adaptar sus productos a las preferencias de los usuarios y para planificar con más precisión su publicidad. Esto exige procesos en tiempo real: en una demostración reciente, el ejercicio de cruzar 16 billones de líneas de pedidos por 56 millones de clientes, dio como resultado un mapa detallado del comportamiento de estos, en apenas 33 segundos.
Hay otros factores en juego: 1) reducir el coste de almacenamiento, para achicar el desfase entre los datos que se crean y los que se pueden conservar; 2) reelaborar los métodos analíticos para extraer de ellos el valor intrínseco que contienen, y 3) hacer que el incremento exponencial no conlleve un aumento paralelo del consumo de energía.
El 90% de los datos que se crean cada día no son estructurados – afirmó Tucci – y “al crecimiento vertiginoso tenemos que añadir la aparición de nuevos tipos de datos, de distintas maneras de gestionarlos, y el número de dispositivos que usan los empleados de las empresas”.
Este fenómeno, de obvia repercusión economica, se apoya en técnicas escalables, para procesar y analizar la información disponible, mucha de ella redundante (que hay que expurgar con métodos distintos a los del entrñable archivero documental de ayer). Por esto, los grandes nombres de la industria informática se han afanado en la captura de compañías pequeñas y especializadas. EMC, líder mundial del almacenamiento de datos, ha desembolsado más de 2.000 millones de euros para absorber Greenplum e Isilon, entre otras; IBM ha comprado Netezza; HP ha integrado Vertica Systems; y Teradata se ha merendado Aster Data. Sólo Oracle – cosa extraña dados sus hábitos compradores y su liderazgo en las bases de datos – no ha movido ficha… todavía.
Uno de los platos fuertes de la conferencia fue el anuncio de una solución analítica de Greenplum – comprada por EMC a finales de 2010 – que se basa en el proyecto Hadoop, desarrollado por Yahoo desde 2005 – sobre un paper publicado por Google – en régimen de open source y coordinado por la Apache Foundation. Otro fue la nueva generación de la plataforma de Isilon – otra subsidiaria de EMC – escalable horizontalmente y orientada a aplicaciones críticas de gran volumen de datos.
A estas alturas, EMC ya no se considera un fabricante de almacenamiento, sino una compañía de sistemas, y esta redefinición ha hecho que pasara a competir con fabricantes de servidores, como HP y Dell, que en poco tiempo han pasado de ser partners a competidores directos. Medio en broma, pero en serio, sus directivos suelen decir que el almacenamiento ha dejado de ser la periferia, para pasar a ocupar el centro de la escena.
En un mercado, el de las TI, que crece perezosamente, EMC facturó 12.000 millones de euros en 2010 (un aumento del 21% sobre el 2009) y obtuvo unos beneficios de 1.300 millones (+75%). Con estas credeciales, ha sido premiada por Wall Street: en los últimos doce meses, el valor de su acción ha subido un 55%.